Generating different styles from stylegan
Results of blending various models in stylegan2

Blending of different models in stylegan was first introduced by Justin Pinkney in his post: StyleGAN network blending. The fundamental idea he proposed was swapping layers between two models. A base model trained on any dataset is blended with another model which is fine-tuned on the base model. For blending, few layers from the base model are swapped with the same layers of the fine-tuned model or vice-versa.
This lets one control what type of features one want from each model. Here in the post Ukiyo-e Yourself, Justin swapped higher resolution layers from stylegan2 trained on FFHQ dataset with higher resolution layers from model fine-tuned on Ukiyo-e photos. Here low-level features like pose, eyes, nose and other details are from FFHQ model and high-level features like texture, skin colour is from a fine-tuned model.
After Justin open-sourced his colab notebook to blend different model of stylegan2, people tried many different styles and got interesting results. Here are some of the blended models details with few results.
Painting
Here is output of model blended from different resolutions.
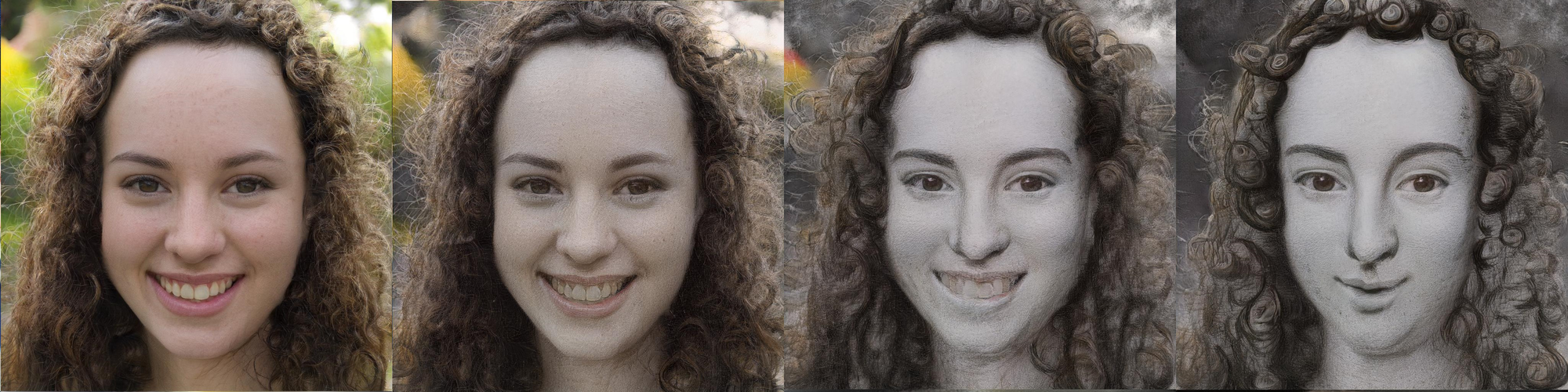
Lower resolutions layer are taken from model trained on FFHQ while higher resolution layers are from model fine-tuned on Met Faces.
Below are some of the cherry pick results.



Cartoon
- Dataset: Cartoon images
- Fine-tuned by: Doron Adler
Here is output of model blended from different resolutions.

Lower resolutions layer are taken from model trained on FFHQ while higher resolution layers are from model fine-tuned on cartoon images.
Below are some of the cherry pick results.



Comic face
- Dataset: Comic and Monster faces
- Fine-tuned by: Doron Adler
Here is output of model blended from different resolutions.

Lower resolutions layer are taken from model trained on FFHQ while higher resolution layers are from model fine-tuned on comic images.
Below are some of the cherry pick results.

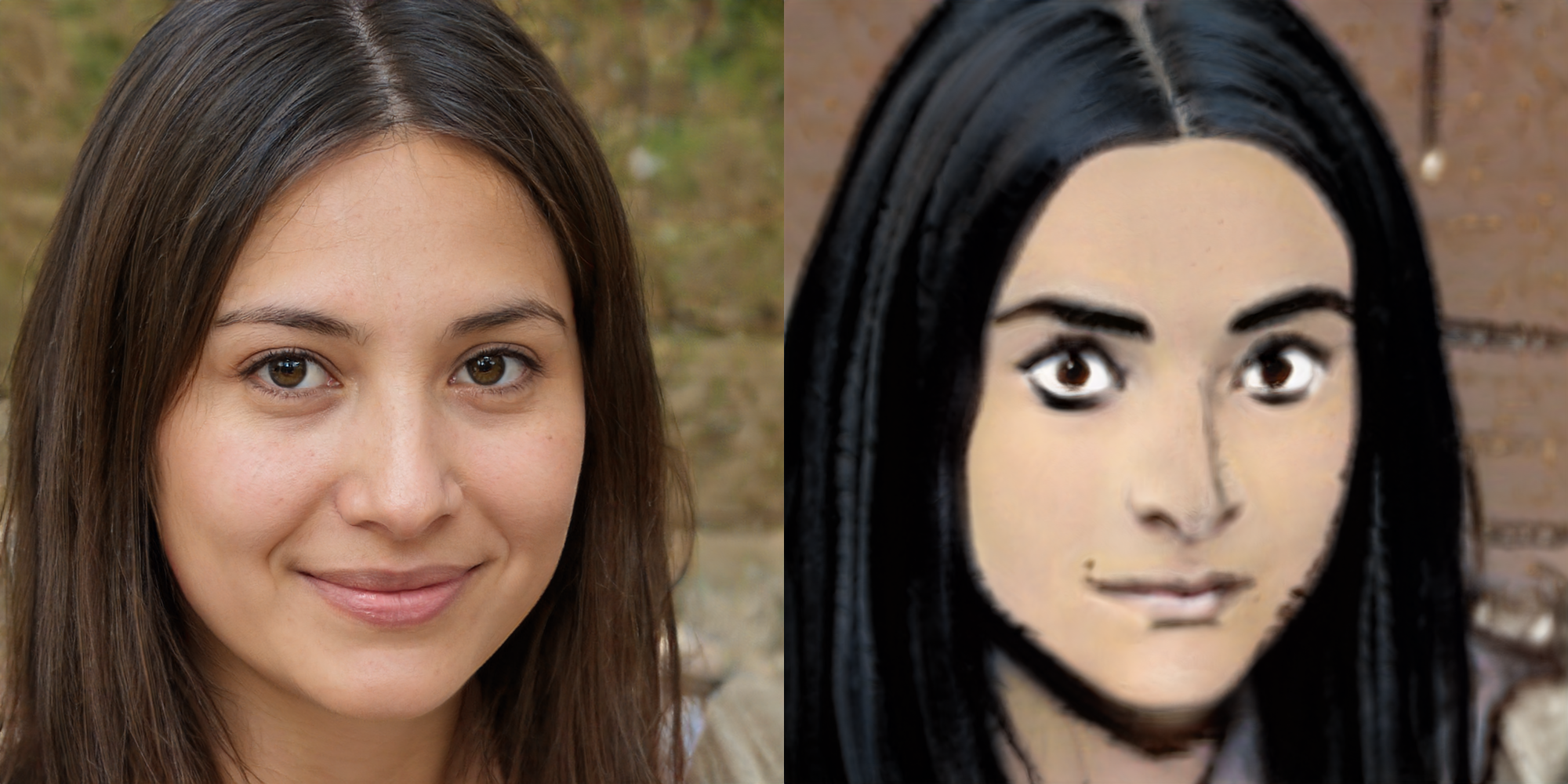

WikiArt
- Dataset: WikiArt
- Fine-tuned by: Peter Baylies
Here is output of model blended from different resolutions.

Lower resolutions layer are taken from model trained on FFHQ while higher resolution layers are from model fine-tuned on wikiArt images.
Below are some of the cherry pick results.



Monster Face
- Dataset: WoWFaces
- Fine-tuned by: Doron Adler
Here is output of model blended from different resolutions.

Below are some of the cherry pick results.



Furby Toys
- Dataset: Furby Images
- Fine-tuned by: Doron Adler
Here is output of model blended from different resolutions.
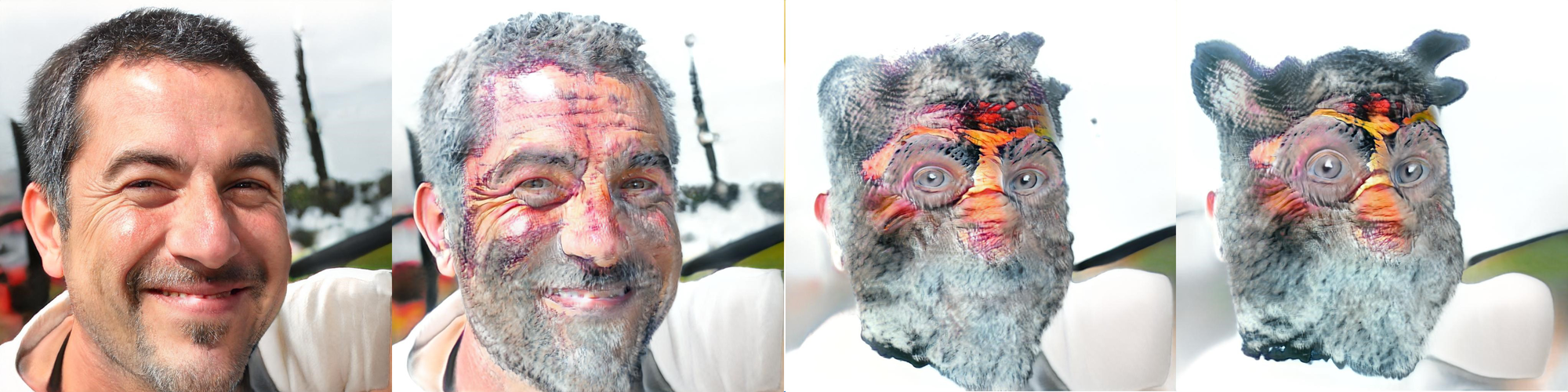
Below are some of the cherry pick results.



Will be updating this post once I fine-tune on more datasets. Have a look after a few days.
Some cool results
-
Interpolation of few AI/ML researchers into different styles
-
Interpolation of few actors and actress into different styles
-
Exploration of cartoon latent space with music
Used ‘Culture Shock’ stylegan visualizer with some modifications.This looks so amazing. Visualizing @Norod78 and @Buntworthy 's #toonify with music effect. Sync in the middle is so perfect.
— Levin (@DabhiLevin) October 9, 2020
(Turn on sound if you haven't ;)) pic.twitter.com/UL4H3RlVZi
Updates
Justin and Doron submitted this idea at Neurips creativity workshop.Out on arxiv, submitted to neurips creativity workshop (cc @elluba), work done with @Norod78 https://t.co/afkOiAXj95
— Justin (@Buntworthy) October 13, 2020